Understanding BERT — (Bidirectional Encoder Representations from Transformers).
Part 2/3 of Transformers vs Google QUEST Q&A Labeling (Kaggle top 5%).

This is a 3 part series where we will be going through Transformers, BERT, and a hands-on Kaggle challenge — Google QUEST Q&A Labeling to see Transformers in action (top 4.4% on the leaderboard).
In this part (2/3) we will be looking at BERT (Bidirectional Encoder Representations from Transformers) *and how it *became state-of-the-art in various modern natural language processing tasks.
Since the architecture of BERT is based on Transformers, you might want to check the internals of a Transformer which you can find in Part 1/3.
We are aware of the fact that how transfer learning has revolutionized the field of computer vision in the past few years. Pretrained networks like VGG, YOLO, UNET, RESNET, and many more have shown a groundbreaking performance in different areas of computer vision. We have also seen a similar approach in the field of NLP like Word2Vector, GloVe but BERT takes it to a whole another level.
BERT was a paper published by researchers at Google AI Language in late 2018 and since then it has become a state of the art in many NLP tasks. BERT takes a different approach, it considers all the words of the input sentence simultaneously and then uses an attention mechanism to develop a contextual meaning of the words. This approach works well for many NLP tasks as shown in the ELMo (Embeddings from Language Models) paper recently.
In this blog, we will cover BERT by going through 4 sub-topics-
-
Difference between BERT and previous embedding techniques.
-
Taking a look under the hood: The internal architecture of BERT.
-
How the pre-trained BERT was trained: Different training methods that made BERT so efficient.
-
The input and output: How to use a BERT
How is BERT different from other embedding generating algorithms like Word2Vector or GloVe?
The main differences between BERT and W2V or GloVe are:
-
W2V and GloVe word embeddings are context-independent. These models output just one vector (embedding) for each word, combining all the different senses of the word into one vector. For example in a given sentence: “the game will lead to a tie if both the guys tie their final tie at the same time.” Word2Vector or GloVe will fail to capture that all the 3 words tie in the sentence have different meanings and would simply return the same embedding for all the 3 words. Whereas BERT is context-dependent, which means each of the 3 words would have different embeddings because BERT pays attention to the neighboring words before generating the embeddings.
-
Because W2V and GloVe are context-independent, we do not require the model which was used to train the vectors every time to generate the embeddings. We can simply train the vectors on a corpus of words once and then generate a table or database holding the words and their respective trained vectors. Whereas in the case of BERT, since it is context-dependent, we need the pre-trained model every time while generating the embeddings or performing any NLP task.
Now that we have got to know BERT a bit, let’s understand how it works.
Taking a look under the hood
The architecture of BERT is derived from transformers. Inside a BERT there are several stacked encoder cells, similar to what we saw in transformers. Remember that inside a transformer how the encoder cells were used to read the input sentence and the decoder cells were used to predict the output sentence (word by word) but in the case of BERT, since we only need a model that reads the input sentence and generates some features that can be used for various NLP tasks, only the encoder part of the transformer is used. The bi-directional part in BERT comes from the fact that it reads all the input words simultaneously.

Like I said before, the encoder cells are similar to what we saw in the transformer. There are self-attention heads and then a feed-forward neural network. The attention heads and feed-forward neural networks are also parameters that define different kinds of BERT models.

If we look at BERT base and BERT large which are the two BERT architectures, both BERT base, and BERT large take an input of 512-dimensions.

-
BERT base — 12 layers (transformer blocks), 12 attention heads, 110 million parameters, and has an output size of 768-dimensions.
-
BERT Large — 24 layers (transformer blocks), 16 attention heads, 340 million parameters, and has an output size of 1024-dimensions.

On SQuAD v1.1, BERT achieves a 93.16% F1 score, surpassing even the human-level score of 91.2%: BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
*The paper calls encoder cells as transformer blocks.
Training the model
BERT is available as a pre-trained model. It was pre-trained on a large corpus of unlabelled text including the entire Wikipedia(that’s 2,500 million words) and book corpus (800 million words). Let’s see the 2 training methods that were used to train BERT.
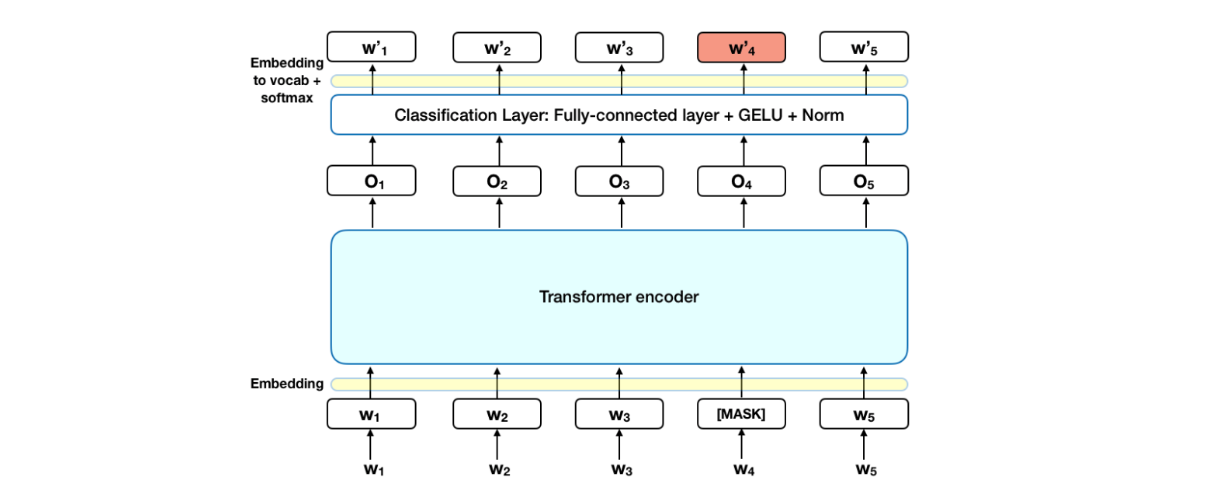
- Masked Language Model (MLM): In this approach, the model is fed with a sentence such that 15% of the words in the sentence are masked. The challenge for BERT is to predict the masked words correctly given the context of unmasked words. Some points to keep in mind are:
- The output from the final encoder block is not directly used for predictions, instead, a fully connected layer with GELU activation is added in between. The output from this layer is then converted to vocab and a softmax function is applied for predicting the masked word.
- The loss function only considers the predicted values for the masked words which make the learning more context-based.
- Next Sentence Prediction (NSP): In this approach, the model is fed with 2 sentences. The challenge for BERT is to predict the order of the 2 sentences. For example, suppose the two sentences are: “I have a pen” and “The pen is red”. While training, BERT is expected to return 1 if the first sentence comes after the second sentence and 0 if the second sentence comes after the first sentence.
While training a BERT model, both of the approaches discussed above are used simultaneously.
The Input and Output
Input:
Having learned about the architecture and the training process of BERT, now let’s understand how to generate the output using BERT given some input text.
Special tokens: There are some special tokens or keywords that are used while generating the input for BERT. The main ones are [CLS] and [SEP]. [CLS] is used as a very first token added at the beginning of the input sentence. [SEP] is used as a separator between different sentences when multiple input sentences are passed. Let’s consider an example: Suppose we want to pass the two sentences “I have a pen” and *“The pen is red” *to BERT. The tokenizer will first tokenize these sentences as: [‘[CLS]’, ‘I’, ‘have’, ‘a’, ‘pen’, ‘[SEP]’, ‘the’, ‘pen’, ‘is’, ‘red’, ‘[SEP]’] and then convert into numerical tokens.

BERT takes 3 types of input:
-
*Token Embeddings: *The token embeddings are numerical representations of words in the input sentence. There is also something called sub-word tokenization that BERT uses to first breakdown larger or complex words into simple words and then convert them into tokens. For example, in the above diagram look how the word ‘playing’ was broken into ‘play’ and ‘##ing’ before generating the token embeddings. This tweak in tokenization works wonders as it utilized the sub-word context of a complex word instead of just treating it like a new word.
-
Segment Embeddings: The segment embeddings are used to help BERT distinguish between the different sentences in a single input. The elements of this embedding vector are all the same for the words from the same sentence and the value changes if the sentence is different. Let’s consider an example: Suppose we want to pass the two sentences “I have a pen” and “The pen is red” to BERT. The tokenizer will first tokenize these sentences as: [‘[CLS]’, ‘I’, ‘have’, ‘a’, ‘pen’, ‘[SEP]’, ‘the’, ‘pen’, ‘is’, ‘red’, ‘[SEP]’] And the segment embeddings for these will look like: [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1] Notice how all the elements corresponding to the word in the first sentence have the same element 0 whereas all the elements corresponding to the word in the second sentence have the same element 1.
-
Mask tokens: The mask tokens that help BERT to understand what all input words are relevant and what all are just there for padding. Since BERT takes a 512-dimensional input, and suppose we have an input of 10 words only. To make the tokenized words compatible with the input size, we will add padding of size 512–10=502 at the end. Along with the padding, we will generate a mask token of size 512 in which the index corresponding to the relevant words will have 1s and the index corresponding to padding will have 0s.
-
Position Embeddings: Finally there are Position Embeddings that are generated internally in BERT and that provide the input data a sense of order. It is the same as what we discussed in Transformers.
Output:
Remember for each word in the input, the BERT base internally creates a 768-dimensional output but for tasks like classification, we do not actually require the output for all the embeddings. So by default, BERT considers only the output corresponding to the first token [CLS] and drops the output vectors corresponding to all the other tokens.
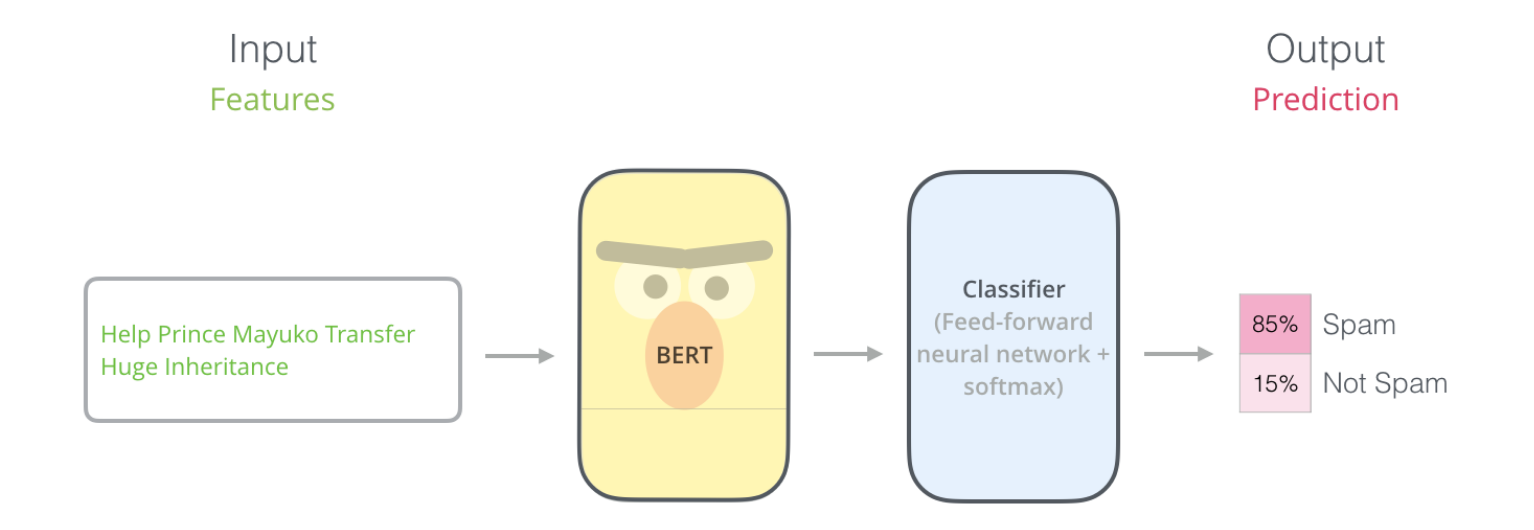
This works pretty neatly for classification tasks like spam detection where for a given an input text, we need to predict if it is spam or not. We generate token_embeddings, segmentation_embeddings, and mask_tokens for the input sentence, pass them into BERT which generates a 768-dimensional output. Finally, we take this output and pass it into a feed-forward network like a Dense layer with 2 nodes and softmax as the activation function.
The catch with the above output is that it does not work as good for tasks where we need to focus more on the semantic meaning of the sentence like machine translation.
For tasks like these, it is advised to use the pooled or averaged output of the hidden states of encoders. This is sometimes also referred to as feature extraction.
After much experimentation on which vector works best as a contextualized embedding, the paper mentions 6 choices.

Turns out that for most of the tasks, concatenation of the hidden states from the last four encoders seems to work the best.
To know more about the input parameters and the values returned my BERT you can check out the official documentation here: https://huggingface.co/transformers/model_doc/bert.html
Usability
Finally, let’s take a look at what all tasks BERT can perform as per the paper.

(a). To classify a pair of sentences eg. a question-answer pair is relevant or not.
(b). To classify a single sentence eg. detect if the input sentence is a spam or not.
(c). To generate an answer to the given question title and paragraph.
(d). Single sentence tagging tasks such as named entity recognition, a tag must be predicted for every word in the input.
That was all to BERT in this blog, Hope the read was pleasant. I would like to thank all the creators for creating the awesome content I referred to for writing this blog.
Reference links:
-
https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
-
https://towardsdatascience.com/understanding-bert-is-it-a-game-changer-in-nlp-7cca943cf3ad
Final note
Thank you for reading the blog. I hope it was useful for some of you aspiring to do projects or learn some new concepts in NLP.
In part 1/3 we covered how Transformers became state-of-the-art in various modern natural language processing tasks and their working.
In part 3/3 we will go through a hands-on Kaggle challenge — Google QUEST Q&A Labeling to see Transformers in action (top 4.4% on the leaderboard).
Find me on LinkedIn: www.linkedin.com/in/sarthak-vajpayee
Peace! ☮